
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
Le Système d’Immatriculation des Véhicules (SIV) dispose des informations concernant les titulaires de certificat d'immatriculations.
Il est nécessaire d'enlever les personnes décédées pour éviter des cas de fraude liées à l'immatriculation des véhicules, et en particulier pour les infractions de la route.
[matchID] permet de radier les personnes décédées chaque mois au fichier d'immatriculation des véhicules.
Avez-vous une grande base de données d'identités et vous souhaitez y retirer les personnes décédés ?
Pour des traitements de données très volumineux vous pouvez installer le produit on-premise sur une infrastructure adaptée pour porter le traitement à large échelle. Le traitement peut se paralléliser pour réduire notablement les temps de traitement.
Quatre étapes seront nécessaires:
Vous pouvez vous lire directement à partir d'une base de données et préparer les requêtes à faire à l'API de traitement. Assurez vous d'avoir au minimum le nom, prénom et date de naissance pour faire le rapprochement. Pour garantir plus la fiabilité du rapprochement et éviter les homonymes parfaits (même date de naissance et même prénom), il est recommandé d'utiliser des données sur le lieu de naissance.
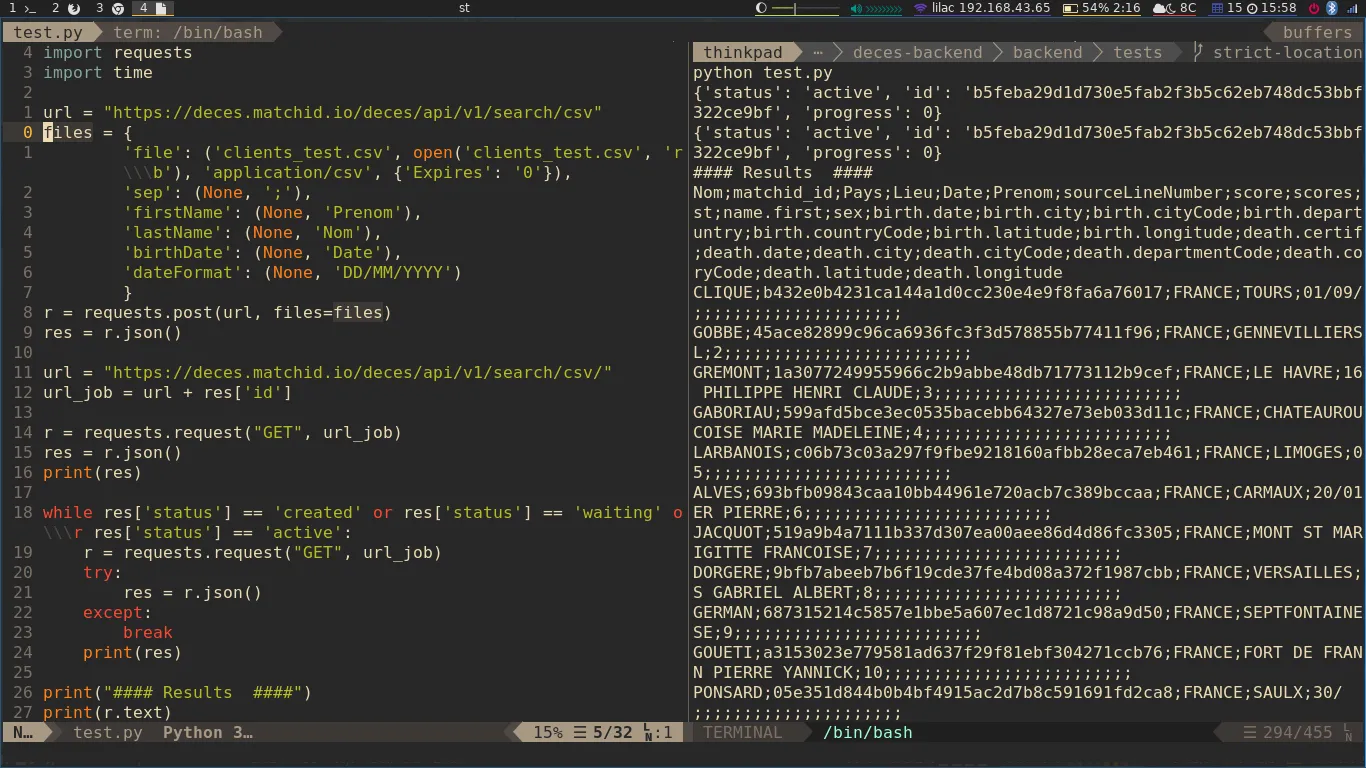
Pour accélérer le traitement, il est conseillé de déployer sur une architecture massive (>32vCPU, 128Go de RAM).
Il est possible d'optimiser la mémoire pris par elasticsearch, il est recommandé de donner la moitie de la RAM du serveur. Sur le code du backend ça correspond à la variable `ES_MEM`
L'API peut découper l'input en chunks et les traiter de façon concurrente. Sur le code du backend ça correspond au paramètre `BACKEND_CONCURRENCY_JOB` et `BACKEND_CONCURRENCY_CHUNKS`.

Paralleliser les requêtes pour profiter au maximum des ressources de la machine. Nous proposons d'utiliser de librairies comme multiprocessing pour le traitement.
Chaque thread va faire la requete et enregistrer le resultat dans une base de données.
Fabien est ingénieur et travaillait au sein de ministères régaliens sur la data et l'IA. Concepteur de matchID et de deces.matchid.io, il développe toujours avec plaisir les algorithmes aussi bien que les UI, sur son temps libre. Depuis 2022, il travaille en IT et IA à Montréal, et reste passionné par les projets d'intérêt général.

Cristian est phD passionné de développement et technologie, expert en deeplearning. Il travaille aujourd'hui au ministère de l'Intérieur, où il a créé IA Flash, et contribue activement à matchID avec la création de l'API décès.

Docteur en droit et diplômé en affaires publiques de l’IEP de Paris, Simon s’est spécialisé dans la transformation des administrations, notamment à travers le numérique. Passionné par ces sujets, il travaille à l’innovation dans les ministères, enseigne à l’université et contribue à MatchID sur les aspects juridiques et financiers.

