
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
L'API décès possède deux principales fonctions:
La première sera utile dans un contexte utilisateur (un formulaire dte données de données d'État civil, où l'appel API servira à vérifier la vitalité d'une personne).
La seconde est utile pour compléter le statut vital d'une base de donnée clients au sein d'un système d'information, de plusieurs milliers à environ un million de personnes
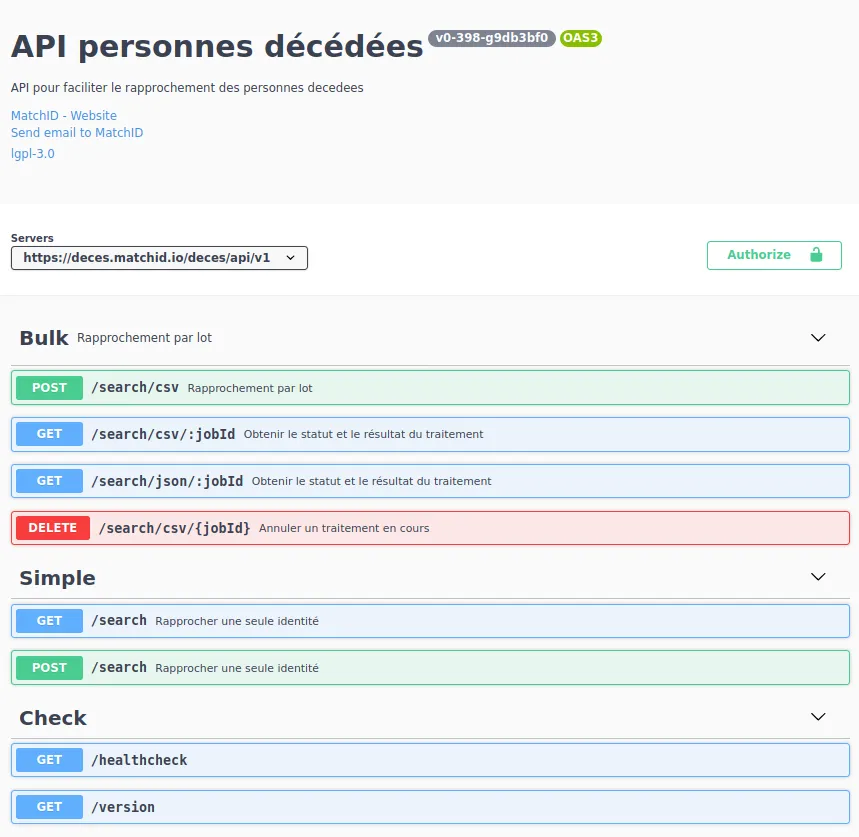
La documentation de l'API est réalisée au format OpenApi Specification (OAS3, Swagger).
Elle décrit de façon détaillée les champs et leur format.
Le cas d'usage basique est l'utilisation, de la recherche simple (q=Pompidou...)
depuis la valeur d'un formulaire (input).

Le code est l'implémentation de cas en Svelte.js. Cliquez sur "output" pour voir le résultat, ou rendez-vous sur ce REPL.
L'exemple utilise l'API search en mode GET, documentée ici.
Sa transposition en POST est simple et préférable pour la robustesse d'un code de production.
L'API est utilisable sans authentification pour un nombre limité d'appels sur l'API de recherche. Pour utiliser l'API au-dela d'une centaine d'appels, ou pour utiliser l'API d'appariement, l'utilisation d'un jeton est nécessaire, tout en restant gratuite.
Voici les étapes si vous voulez automatiser l'obtention de la clé d'API pour un an:
eyJhbGc*
Vous pouvez rafraîchir votre jeton initial sans limite de la façon suivante:
Authorization: "Bearer accessToken", en remplaçant accessToken par votre jeton. Des limitations demeurent sur la fréquence d'appel (1/s pour la recherche) mais le nombre d'appels devient illimité.
https://deces.matchid.io/deces/api/v1/auth?refresh=true - ne nouveau jeton récupéré permettra de réitérer les opérations jusqu'à 12 mois.
Vous pouvez faire une demande de rafraîchissement tous les jours par exemple, il n'y a pas de limite (il est inutile d'en faire une demande a chaque appel, mais ce peut être à chaque session si vous faites des appels consécutifs de 5 minutes ou même moins).
Voici un exemple de code Python qui permet de gérer automatiquement le renouvellement du token :
import requests
import json
from datetime import datetime, timedelta
import os
MANUAL_TOKEN = os.getenv('MANUAL_TOKEN')
class TokenManager:
def __init__(self, initial_token):
self.token = initial_token
self.last_refresh = datetime.now()
self.refresh_interval = timedelta(days=1) # Rafraîchir tous les jours
def get_token(self):
# Vérifier si le token doit être rafraîchi
if datetime.now() - self.last_refresh > self.refresh_interval:
self.refresh_token()
return self.token
def refresh_token(self):
headers = {
"Authorization": f"Bearer {self.token}"
}
response = requests.get(
"https://deces.matchid.io/deces/api/v1/auth",
params={"refresh": "true"},
headers=headers
)
if response.status_code == 200:
data = response.json()
self.token = data["access_token"]
self.last_refresh = datetime.now()
print(f"Token rafraîchi avec succès. Nouvelle date d'expiration: {data['expiration_date']}")
else:
print(f"Erreur lors du rafraîchissement du token: {response.text}")
# Exemple d'utilisation
if __name__ == "__main__":
# Token initial obtenu manuellement
initial_token = "eyJhbGc..." # Votre token initial
# Créer une instance du gestionnaire de token
token_manager = TokenManager(initial_token)
# Exemple d'utilisation dans une requête API
def faire_requete_api():
headers = {
"Authorization": f"Bearer {token_manager.get_token()}"
}
response = requests.get(
"https://deces.matchid.io/deces/api/v1/search",
params={"q": "Georges Pompidou"},
headers=headers
)
return response.json()
# La requête utilisera automatiquement un token valide
resultat = faire_requete_api()
print(json.dumps(resultat, indent=2))
Ce code implémente une classe TokenManager qui :
L'API unitaire est limité à une requête par seconde. Pour les appariement en masse,
une API search/csv permette le traitement de 50 à 100 requêtes par seconde.
Cette API de soumettre un CSV contenant jusqu'à 1 millions d'identité (100Mo), qui sera complété d'éventuelles détections des données de décès en cas de correspondance celle-ci étant qualifiée par un score de confiance.

Ces données peuvent être retraitées à l'issue pour être injectées dans votre base de donnée.
Voici un exemple minimaliste en Python pour utiliser l'API d'appariement:
import requests
import time
import os
from TokenManager import TokenManager
API_URL = "https://deces.matchid.io/deces/api/v1/search/csv"
token_manager = TokenManager()
API_TOKEN = token_manager.get_token()
# Formulaire multipart avec mapping des colonnes et paramètres CSV
files = {
'file': ('misc_sources_test.csv',
open('misc_sources_test.csv', 'rb'),
'application/csv', {'Expires': '0'}),
'sep': (None, ','), # séparateur csv
'firstName': (None, 'PRENOM'), # mapping des champs
'lastName': (None, 'NOM'),
'birthDate': (None, 'DATE_NAISSANCE'),
'birthCity': (None, 'COMMUNE_NAISSANCE'),
'birthDepartment': (None, 'DEP_NAISSANCE'),
'birthCountry': (None, 'PAYS_NAISSANCE'),
'sex': (None, 'GENRE'),
'candidateNumber': (None, '5'),
'pruneScore': (None, '0.3'),
'dateFormat': (None, 'DD/MM/YYYY') # format de date
}
headers = {"Authorization": f"Bearer {API_TOKEN}"}
r = requests.post(API_URL, files=files, headers=headers)
print(r.text)
res = r.json()
# Récupération de l'ID pour suivre l'avancement du traitement
print(res['id'])
url_job = API_URL + res['id']
print("url: ", url_job)
r = requests.request("GET", url_job, headers=headers)
print(r.text)
res = r.json()
print(res)
while res['status'] == 'created' or res['status'] == 'waiting' or res['status'] == 'active':
r = requests.request("GET", url_job, headers=headers)
try:
# Vérification de l'état du traitement via JSON
res = r.json()
except:
# Job terminé si réponse non-JSON
break
time.sleep(2)
print(res)
# CSV source complété des données de décès
print(r.text.replace(";","\t"))
L'enregistrement préalable du webhook est nécessaire. Il sera authentifié à l'aide d'un challenge.
Nous recommendons l'usage de https://webhook.site pour bien comprendre le mécanisme préalablement.
Notez que nous ne persistons pas ces enrolements, donc il est nécessaire de vérifier le webhook avant chaque appariement, ou tous les mois.
Déclarez d'abord l'URL du webhook :
curl https://deces.matchid.io/deces/api/v1/webhook \
-H "Authorization: Bearer <token>" \
-d '{"url":"https://webhook.site/<uuid>","action":"register"}'
Le service renvoie un challenge. Modifiez votre endpoint pour renvoyer ce challenge texte ou JSON devant contenir le
challenge), puis validez le webhook ainsi:
curl https://deces.matchid.io/deces/api/v1/webhook \
-H "Authorization: Bearer <token>" \
-d '{"url":"https://webhook.site/<uuid>","action":"challenge"}'
Une fois le challenge détecté, le statut passe à validated.
Pour soumettre le job, décommentez dans le code proposé au paragraphe précédent le champ webhook
dans le multipart/form-data.
Voici l'implémentation minimale de votre webhook dans une API flask
from flask import Flask, request, Response
import requests
from TokenManager import TokenManager
app = Flask(__name__)
token_manager = TokenManager() # Différent : utilisation du TokenManager
def download_csv(job_id: str) -> None:
url = f"{API_URL}/{job_id}"
headers = {"Authorization": f"Bearer {token_manager.get_token()}"} # Différent : token dynamique
r = requests.get(url, headers=headers)
if r.ok:
with open(f"results_{job_id}.csv", "wb") as f:
f.write(r.content)
app.logger.info("CSV téléchargé : results_%s.csv", job_id)
else:
app.logger.error("Erreur téléchargement CSV : %s", r.text)
@app.route("/callback", methods=["POST"])
def callback():
data = request.get_json(force=True, silent=True) or {}
if "challenge" in data:
return data["challenge"], 200
event = data.get("event")
job_id = data.get("jobId")
if event == "completed" and job_id:
download_csv(job_id)
elif event == "failed":
app.logger.error("Job échoué : %s", job_id)
elif event == "deleted": # Nouveau : gestion de la suppression RGPD
app.logger.info("Fichier supprimé : %s", job_id)
return Response("OK", status=200)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
Notez que notre service ne gère pas de retry en cas d'indisponibilité de votre endpoint. Par ailleurs vous serez également notifié sur le webhook de la suppression du fichier par un "event": "deleted" (par exemple pour traçabilité RGPD).
L'appariement requiert de trois étapes:
Seules les deux dernières étapes sont réalisées au moment de l'utilisation de l'API search/csv
La requête est composée d'un bloc de critères obligatoires (blocking), les autres éléments de la requête étant optionnels. Les critères obligatoires sont ceux-ci:
lastSeenAliveDate est spécifiée, elle devient obligatoire
Note 1: si l'un des champs nom ou prénom manquent, tous les champs disponibles deviennent obligatoires, avec une tolérance floue.
Note 2: les données INSEE utilisent le nom de naissance. Le nom d'usage génère du silence (manqués), notamment sur la popuation des femme mariées.
Note 3: le code source des requêtes est sur GitHub.
Le scoring est composé de trois composantes relatives aux données de l'identité pivot: nom & prénom, sexe, date et lieu de naissance.
Les champs textuels (nom prénom, libellés de commune et pays) sont traités en normalisation et tokenization, puis comparés avec la distance de Levenshtein, et sont pénalisés en cas de différence de sonorité (soundex-fr).
Le lieu de naissance prend en compte les trois paramètres éventuels (commune, département, pays) et effectue un traitement différencié en cas de naissance à l'étranger.
Les scores (nom+prénom, sexe, date, lieu) sont ensuite multipliés, et un coefficient de puissance est affecté selon le nombre de paramètres de match (moins il y a de champs soumis à requête, plus une erreur unitaire est pénalisante). Lorsque l'une des données n'est pas fournie, une faible pénalité est soumise (entre 50% et 100% selon le champ).
Le code source du scoring est également sur GitHub.
Nous vous recommandons dans un premier temps de passer par le service en ligne pour tester la validité du fichier et du choix des colonnes à apparier avant d'attaquer le code d'appariement. Vous pourrez, en particulier, vérifier avec l'aide de l'UI de validation.
Dans le cas d'un service métier intégré dans un système d'information, pour des appariement réguliers, nous recommandons d'intégrer une UI de validation telle que celle proposée.En effet, l'UI proposée permet de diviser en moyenne par 10 le temps de validation d'une paire d'identité par rapport à un affichage en colonnes classiques sous un tableur.
Pour traiter un fichie de 100000 lignes, si 10% de personnes sont décédées, environ 9000 seront avec de très bon scores (peu utiles à valider à la main, sauf cas métier nécessitant une assurance complète), et 1000 seront à regarder plus précisément. Ces 1000 cas peuvent prendre moins de 30 minutes avec une UI adaptée, contre une demie jourée sur un tableur.
A ce stade, nous n'avons pas mis à disposition de composant réutilisable pour cette fonction. Néanmoins nos deux implémentations d'interface de validation peuvent vous inspirer: en Svelte.js ou en Vue.js.
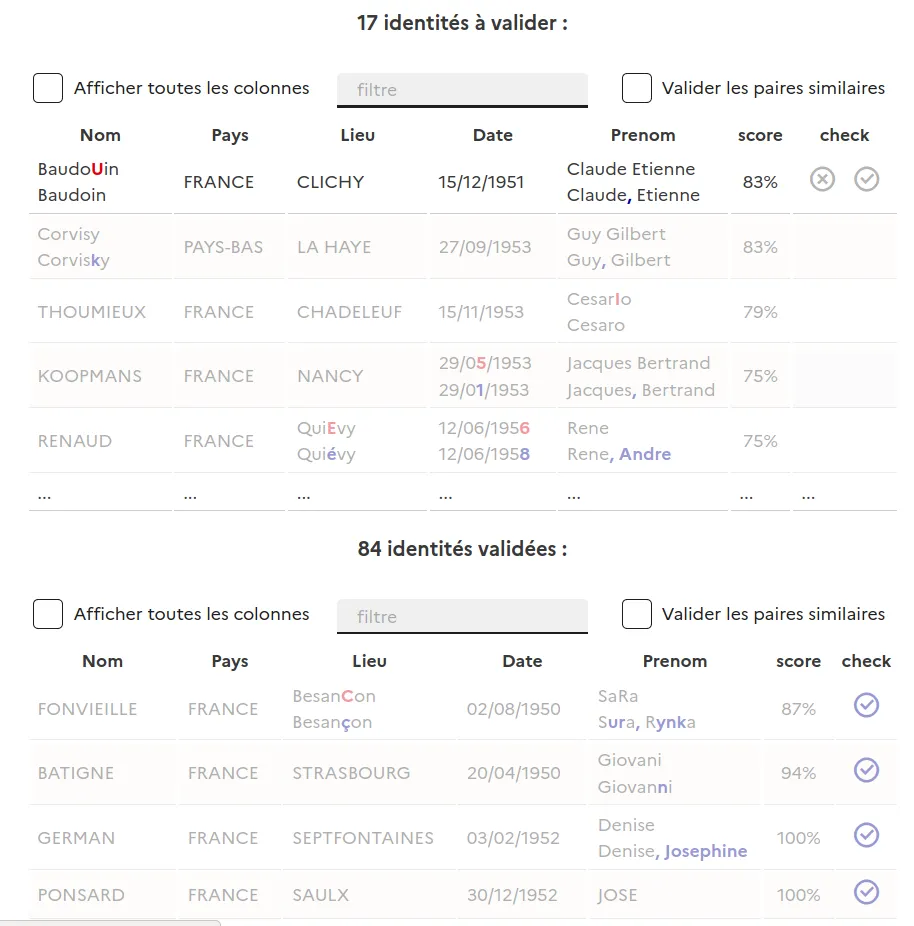
Les composants développés implémentent une mise en exergue des différences champs par champ (nom, prénom, ...) entre la donnée cherchée et la donnée de référence INSEE. Cette facilitation visuelle est la source d'accélération de la validation. Nos implémentations reposent sur la librairie diff.js.
Fabien est ingénieur et travaillait au sein de ministères régaliens sur la data et l'IA. Concepteur de matchID et de deces.matchid.io, il développe toujours avec plaisir les algorithmes aussi bien que les UI, sur son temps libre. Depuis 2022, il travaille en IT et IA à Montréal, et reste passionné par les projets d'intérêt général.

Cristian est phD passionné de développement et technologie, expert en deeplearning. Il travaille aujourd'hui au ministère de l'Intérieur, où il a créé IA Flash, et contribue activement à matchID avec la création de l'API décès.

Docteur en droit et diplômé en affaires publiques de l’IEP de Paris, Simon s’est spécialisé dans la transformation des administrations, notamment à travers le numérique. Passionné par ces sujets, il travaille à l’innovation dans les ministères, enseigne à l’université et contribue à MatchID sur les aspects juridiques et financiers.

