
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
Traitements d'identités numériques
Fiabilisation, recherche et appariements jusqu'à 100 millions d'identités
Ce tutoriel traite un cas simple d'apariement de deux jeux de données d'identité, l'un appelé deaths et l'autre clients. Le type de cas d'usage traité est la suppression des décès d'un fichier client, pour de la mise en qualité. Des cas similaires peuvent être envisager avec un SIRH et un annuaire, par exemple.
Il s'adresse à des développeurs ou datascientists souhaitant s'initier à l'appariement d'identité, à un premier niveau de développement. Pour tout cas d'appariement, nous recommandons de passer par un premier appariement "simple" pour bien évaluer la problématique, et d'itérer en fonction du cas d'usage précis (nombre à apparier, qualité des données, enjeux métiers en précision et rappel, ...).
Premature optimization is the root of all evil (or at least most of it) in programming.
Donald Knuth, 1974
Si vous n'êtes pas datascientist ou développeur, mais souhaitez détecter les décès au sein de votre fichier client, c'est possible sans coder, ici :
Sauf méthode d'appariement en n x n , qui atteignent leur limites dès quelques centaines de milliers d'identité dans l'une des bases, la meilleure option reste l'usage d'une base de donnée. La base la plus compatible avec la plupart des cas d'usages reste Elasticsearch. PostGres pouvant être bien meilleure pour certains cas particuliers, consultez la section algorithmes après ce premier tutoriel. L'ouvrage Data matching de Peter Christen reste également un ouvrage de référence pour les curieux.
Les étapes à observer systématiquement sont :
1. Préparer et indexer la donnée de référence (deaths)
2. Préparer et matcher le fichier à apparier (clients)
3. Scorer la pertinence de chaque appariement et évaluer (clients x deaths)
La préparation de données est essentielle. L'observation fine des données d'identités est impérative. Dans cette phase initiale, il convient d'envisager au maximum l'enrichissement des données, et si possible de réconcilier les personnes par un identifiant technique (de type NIR, ...), parfois il arrive qu'on oublie cette base... Vous pourrez consulter la section des données d'identités après ce premier exercice.
Dans le tutoriel avancé nous implémenterons des techniques plus avancées pour la qualité des données, et évaluerons la qualité des appariement avec une interface d'annotation. Cette dernière étape est impérative dans un contexte de gros volumes, où chaque appariement ne pourra pas être confirmé manuellement. Cerise sur le gâteau, nous utiliserons un peu de machine learning même si l'utilité n'est avérée que dans les cas de très gros volume (la quantité d'annotation nécessaire étant importante).
matchID est conçu autour d'une philosophie de recettes à préparer par petite itération. Pour la suite, nous utiliserons une méthode systématique :
- définir des jeux de donnée d'entrée et cible
- faire une recette minimale
- tester en direct sur échantillon
- lancer la recette sur l'ensemble des données
De jeu de donnée à jeu de donnée, en passant par des recettes, nous implémenterons l'algorithme de data matching.

matchID rassemble ses recettes et déclaration de recettes au sein de projets, ou dossier. Créons un premier projet que nous appelèleron death. Vous devriez obtenir la vue ci-contre.
Note: matchID n'assure pas de gestion de version. A ce stade, le mieux est de référencer chaque projet
comme repository git et de commiter après validation de chaque traitement.

Cliquez sur import dataset et glissez-collez le fichier deaths que vous aurez téléchargé sur Github.
Note: matchID n'assure pas de gestion de version. A ce stade, le mieux est de référencer chaque projet
comme repository git et de commiter après validation de chaque traitement.

Vous pouvez alors voir le jeu de données apparaître sur l'interface, comme ci-contre.
Observez la décomposition de l'écran: à droite pour la donnée, à gauche pour les recettes. Ces dernières peuvent être étendues en 2/3 d'écran ou plein écran en fonction des recettes à coder. Le sonnées quant à elles sont filtrables par contenu, et par nom de colonnes (avec des regexp).
Note: les données sont des données anonymisées et représentatives statistiquement de données réelles
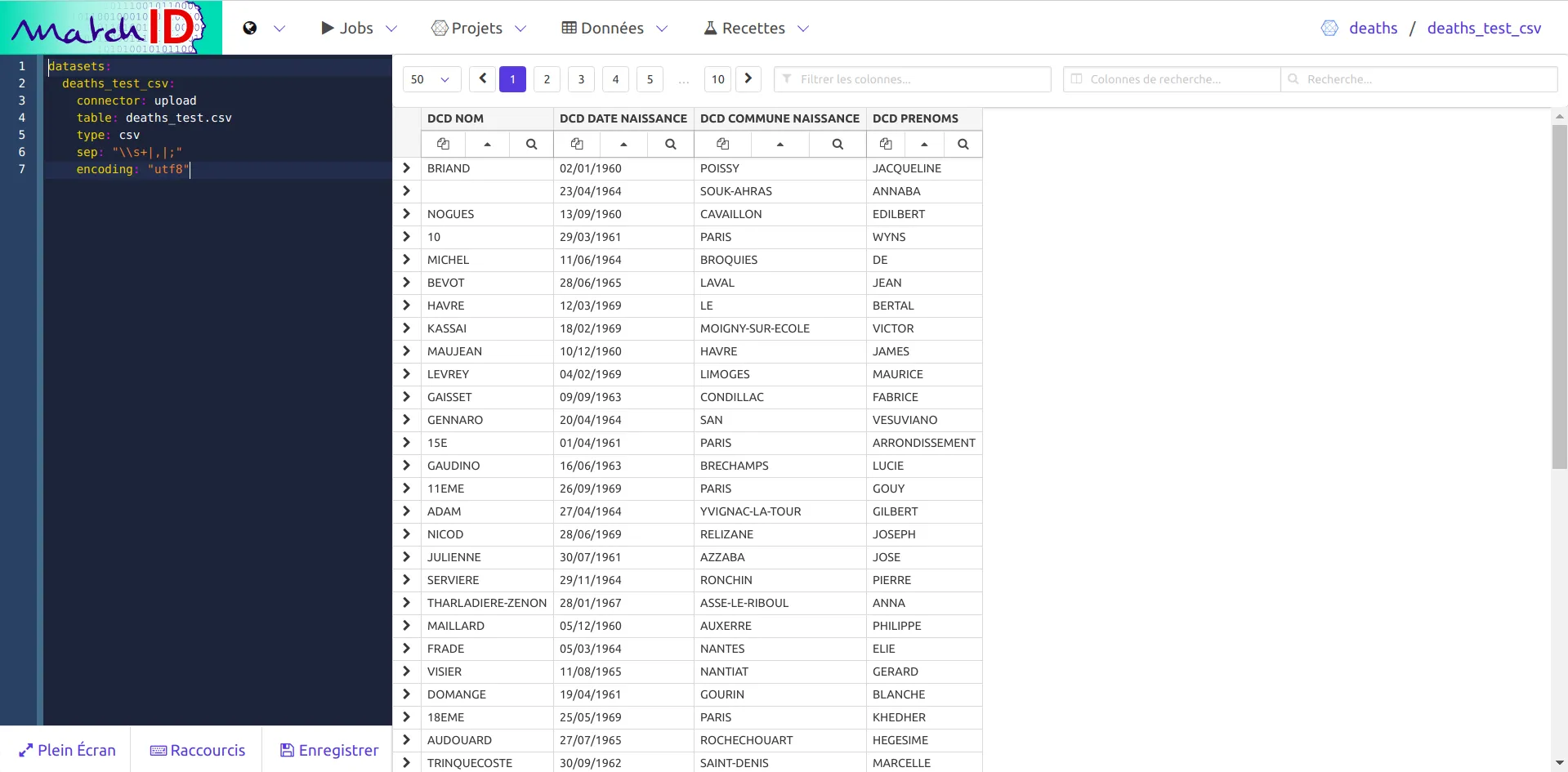
À partir du menu Recettes choisissez Nouvelle recette.
vous pouvez alors créer un nouveau traitement. Dans ce cas, les données sont de qualité, nous ne faisons qu'ajouter un identifiant. Il faut en revanche déclarer la source de données pour pouvoir voir le traitement. Vous pouvez copier la recette ci-dessous :
recipes:
dataprep_deaths_test:
input: deaths_test_csv
output: deaths
# le dataset devra être
# déclaré après la recette
steps: # début des étapes de la recette
- eval: # recette d'évaluation python
- matchid_id: sha1(row)
# on crée la colonne matchid_id
# avec le hash de a ligne
La recette peut être sauvée (menu Sauver ou Ctrl+S), ce qui devrait rendre le résultat suivant:
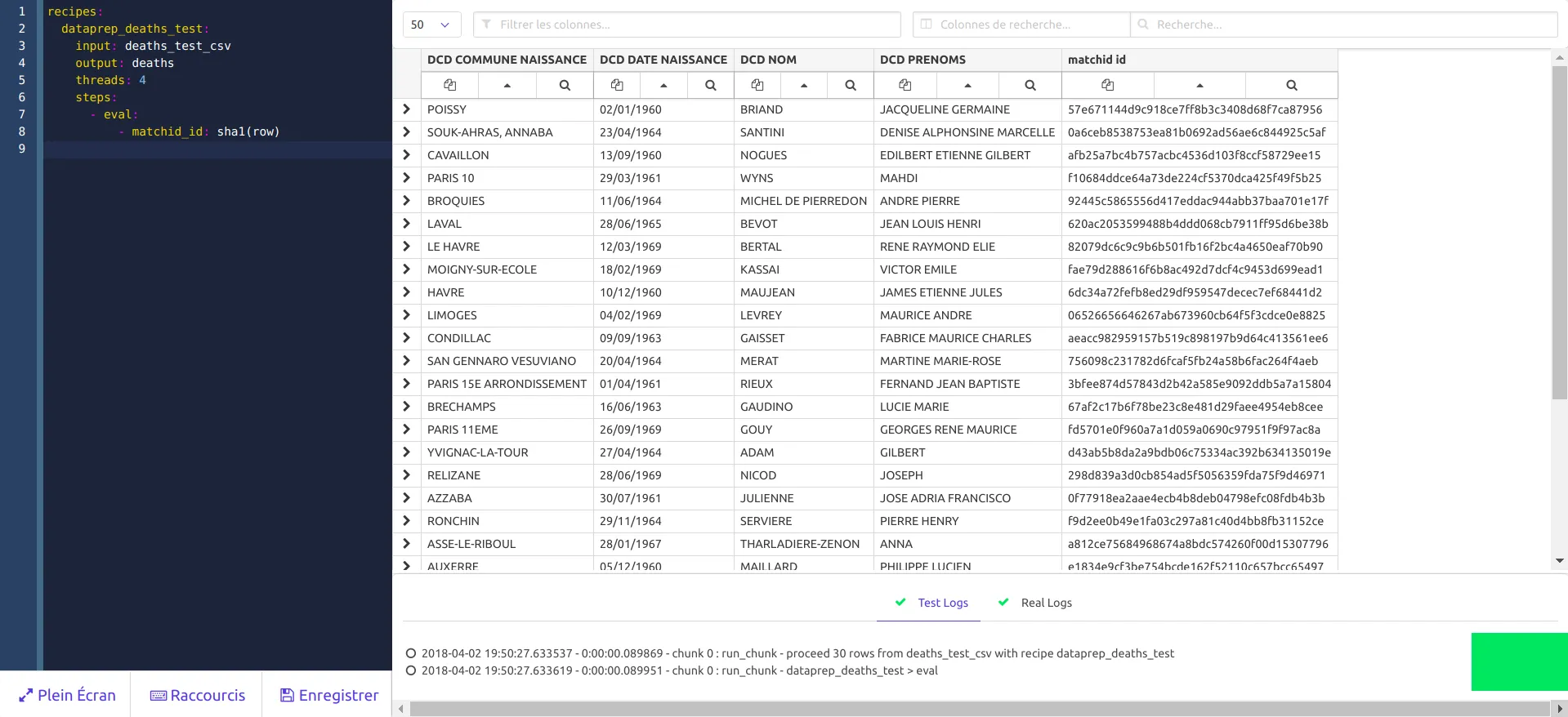 Vous pouvez trouver la liste exhaustive des recettes ici, et des recettes en contexte dans le tutoriel avancé.
Vous pouvez trouver la liste exhaustive des recettes ici, et des recettes en contexte dans le tutoriel avancé.
Créez l’index Elasticsearch pour déclaré en sortie de la recette précédente :
datasets:
deaths:
connector: elasticsearch
table: deaths # nom de l'index
N’oubliez pas de sauver (Sauver ou Ctrl+S).
Puis revenez sur la recette dataprep_death_test. Lancez la recette en appuyant sur :
Vous pouvez suivre l’avancement en bas à droite dans l’onglet Real logs ou via le menu Jobs:

L’indexation dure un peu plus d’une minute pour 71 404 enregistrements.
Le jeu de donnée est clients est dispoinible ici. Importez le fichier par glisser-déposer (cf ci-contre).

Créez l’index clients_x_deaths from the menu
datasets:
clients_x_deaths:
connector: elasticsearch
table: clients_x_deaths
Il faut requêter chaque ligne de clients auprès de l’index deaths. Crééz la recette clients_deaths_matching_test:
recipes:
clients_deaths_matching_test:
input: clients_test_csv
output: clients_x_deaths
steps:
- join:
type: elasticsearch
dataset: deaths
keep_unmatched: False
# passer à "True" pour
# conserver les identités
# sans match
query:
size: 1
query:
bool:
must:
- match:
DCD_NOM: Nom
- match:
DCD_DATE_NAISSANCE: Date
Sauvez et observez les premiers résultats:
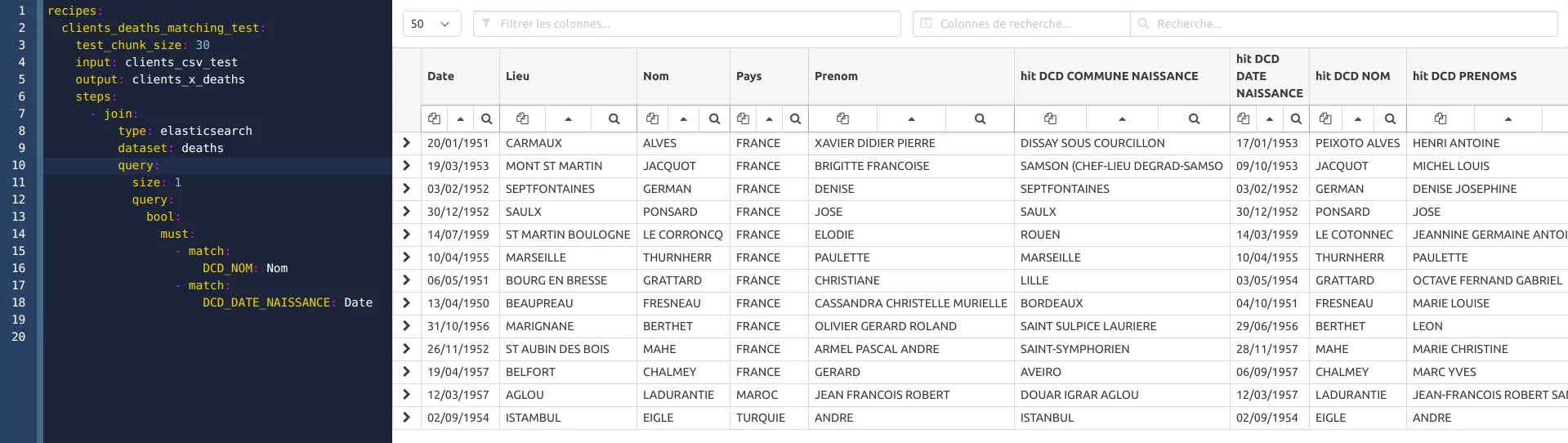 Le match est perfectible: trop de restriction avec le premier prénom, et la tolérance sur la date est trop forte. La R&D sur la phase de matching est essentielle. En
Le match est perfectible: trop de restriction avec le premier prénom, et la tolérance sur la date est trop forte. La R&D sur la phase de matching est essentielle. En SQL, c’est l’optimisation des requêtes de blocking.
matchID aide à l'optimisation de ces requêtes et donc du rappel en en facilitant la visualisation. Pour cet tutoriel, nous proposons cette requete plus complète et précise:
recipes:
clients_deaths_matching_test:
input: clients_test_csv
output: clients_x_deaths
steps:
- join:
type: elasticsearch
dataset: deaths
keep_unmatched: False
query:
size: 1
query:
bool:
must:
- match:
DCD_NOM:
query: Nom
fuzziness: auto
# jusqu'à 2 erreurs
# d'édition
- match:
DCD_DATE_NAISSANCE: Date
- match:
DCD_PRENOMS:
query: Prenom
fuzziness: auto
should:
- match:
DCD_COMMUNE_NAISSANCE: Lieu
# la commune est un match
# améliore le ranking si
# correspond
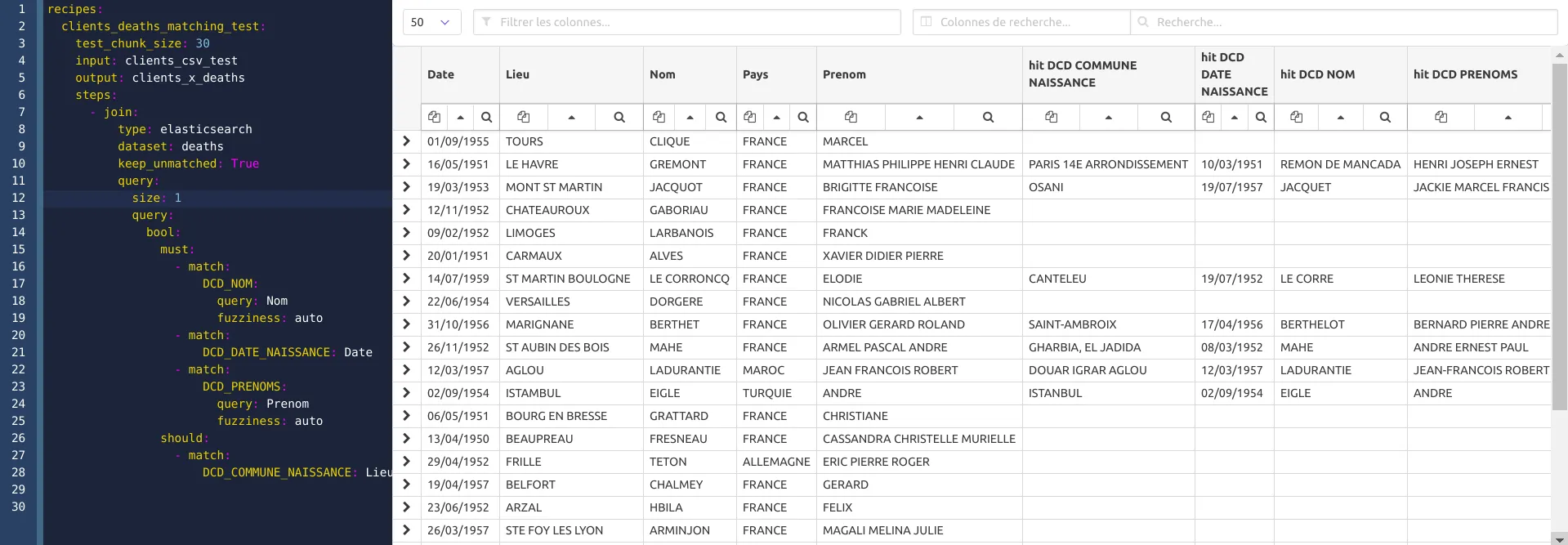
Nous pouvons ajouter dans la même recette la nouvelle étape de scoring après la jointure, avant même d’avoir lancé la requête sur toutes les données.
Le scoring proposé est simple (distance d’édition sur nom, lieu et date de naissance), nous ajoutons un filtre pour les scores bas, ce qui améliore la précision.
- eval:
# scores
- score_date: levenshtein_norm(hit_DCD_DATE_NAISSANCE, Date)
- score_nom: levenshtein_norm(hit_DCD_NOM, Nom)
- score_prenom: jw(hit_DCD_PRENOMS, Prenom)
- score_lieu: jw(hit_DCD_COMMUNE_NAISSANCE, Lieu)
- confiance: round(100 * score_lieu * score_nom * score_prenom * score_date)
Cela rajoute des colonnes de score et une de confiance qui fusionne les scores. Quelques généralités sur la comparaison de caractères: trois type d’algorithmes sont utilisés pour des finalités différentes : la distance de Levenshtein est préférable en cas d’assez forte fiabilité, Jarrow Winlker. La distance phonétique (Soundex Fr) est utile en complément d’un Levensthein, rarement utile seule.
Les critères mis en place permettent d’organiser par pertinence les appariements identifiés. Néanmoins, la phase de matching étant optimisée pour le rappel, elle ramène inévitablement des paires peu pertinentes, et comme il s’agit d’un croisement de deux jeux de données, le taux de confusion explose forcément avec les scores faibles, et des noms très communs. Rendez-vous à la [section algorithmique][algorithms] pour plus de compréhension de la problématique.
Si l’on souhaite filtrer on peut ajouter :
- keep:
where: confiance > 20
Si on souhaite conserver les lignes qui n’ont pas d’appariement pertinent (cf keep_unmatched: True plus haut)
- eval:
# blank low score lines
- hit_DCD_COMMUNE_NAISSANCE: hit_DCD_COMMUNE_NAISSANCE if (confiance > 30) else ""
- hit_DCD_DATE_NAISSANCE: hit_DCD_DATE_NAISSANCE if (confiance > 30) else ""
- hit_DCD_NOM: hit_DCD_NOM if (confiance > 30) else ""
- hit_DCD_PRENOMS: hit_DCD_PRENOMS if (confiance > 30) else ""
- hit_matchid_id: hit_matchid_id if (confiance > 30) else ""
</div>
Rendez-vous sur le dataset client_x_deaths.
Pour mieux voir les résultats, copiez dans la case Filtrer les colonnes le filtre suivant :
Nom|DCD_NOM|Prenom|DCD_PRENOM|Date|DCD_DATE
<img width="100%" src="assets/images/frontend-clients_x_deaths.webp" alt="matchID matching result"> Les résultats sont déjà visibles, mais leur validation est complexe dans ce mode "tableur". Pour faciliter l'évaluation matchID propose une **application de validation**. Il suffit de configurer les colonnes à afficher dans le dataset:
datasets:
clients_x_deaths:
connector: elasticsearch
table: clients_x_deaths
validation:
columns:
- field: matchid_id
label: Id
display: false
searchable: true
- field:
- Nom
- hit_DCD_NOM
label: nom
display: true
searchable: true
callBack: formatDiff
- field:
- Prenom
- hit_DCD_PRENOMS
label: prenom
display: true
searchable: true
callBack: formatDiff
- field:
- Date
- hit_DCD_DATE_NAISSANCE
label: date
display: true
searchable: true
callBack: formatDate
appliedClass:
head: head-centered
body: has-text-centered
- field:
- Lieu
- hit_DCD_COMMUNE_NAISSANCE
label: Lieu
display: true
searchable: true
callBack: coloredDiff
- field: confiance
label: Score
display: true
searchable: false
type: score
callBack: formatNumber
appliedClass:
head: head-centered
body: has-text-centered
min-column-width-100
view:
display: true
column_name: view
fields:
operation: excluded
names:
- none
scores:
column: confiance
range:
- 0
- 100
colors:
success: 80
info: 60
warning: 30
danger: 0
statisticsInterval: 5
preComputed:
decision: 55
indecision: [40, 65]
Notes:
- cette configuration n'est pas nécessaire lorsque le nom des colonnes est conforme, comme dans le [tutoriel avancé](/advanced_tutorial)
- pensez bien à copier coller tout le texte, en scrollant !
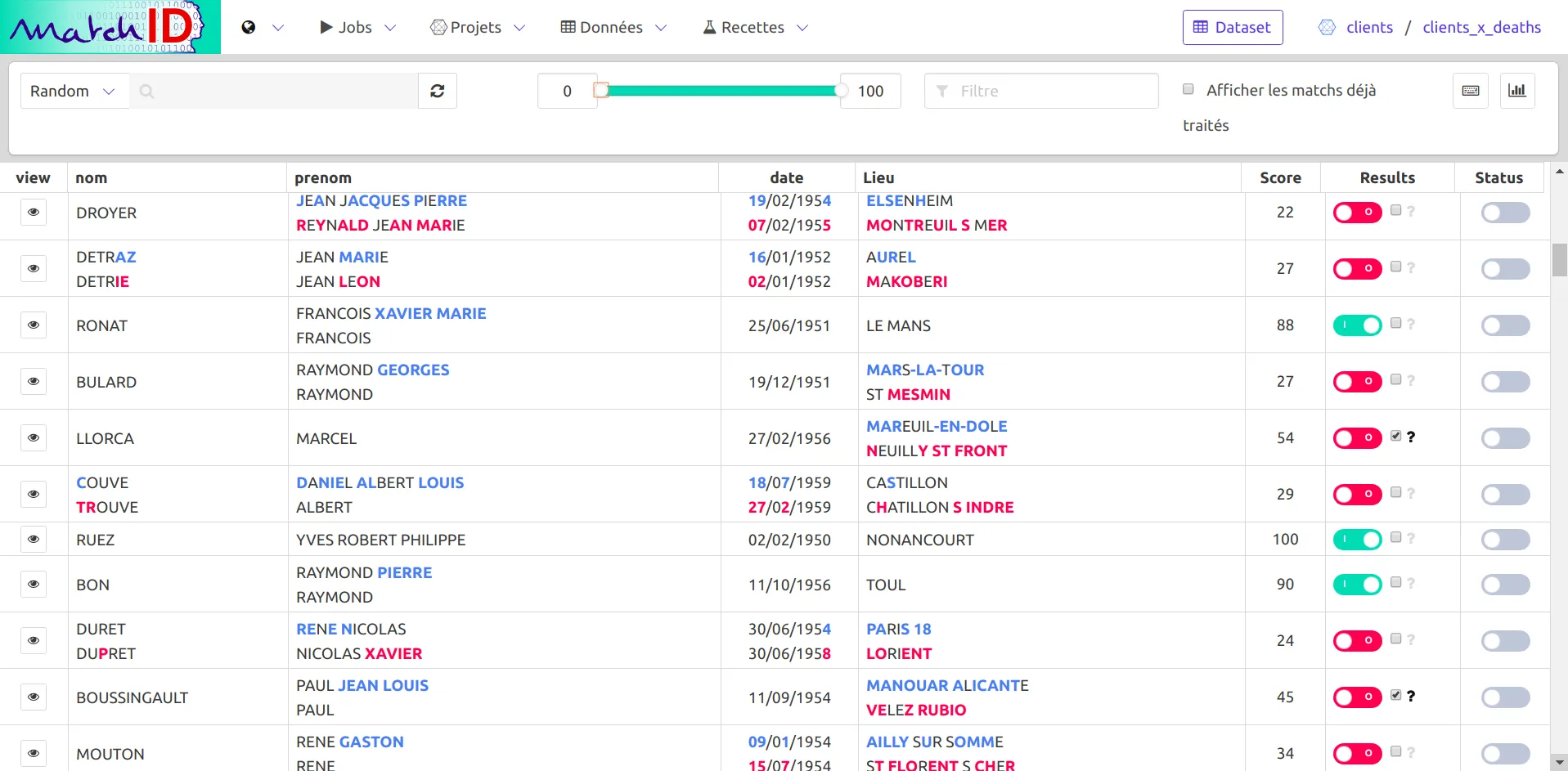
Sauvez la configuration Ctrl+S et rechargez la page (Ctrl+R). Un bouton Validation apparaît:
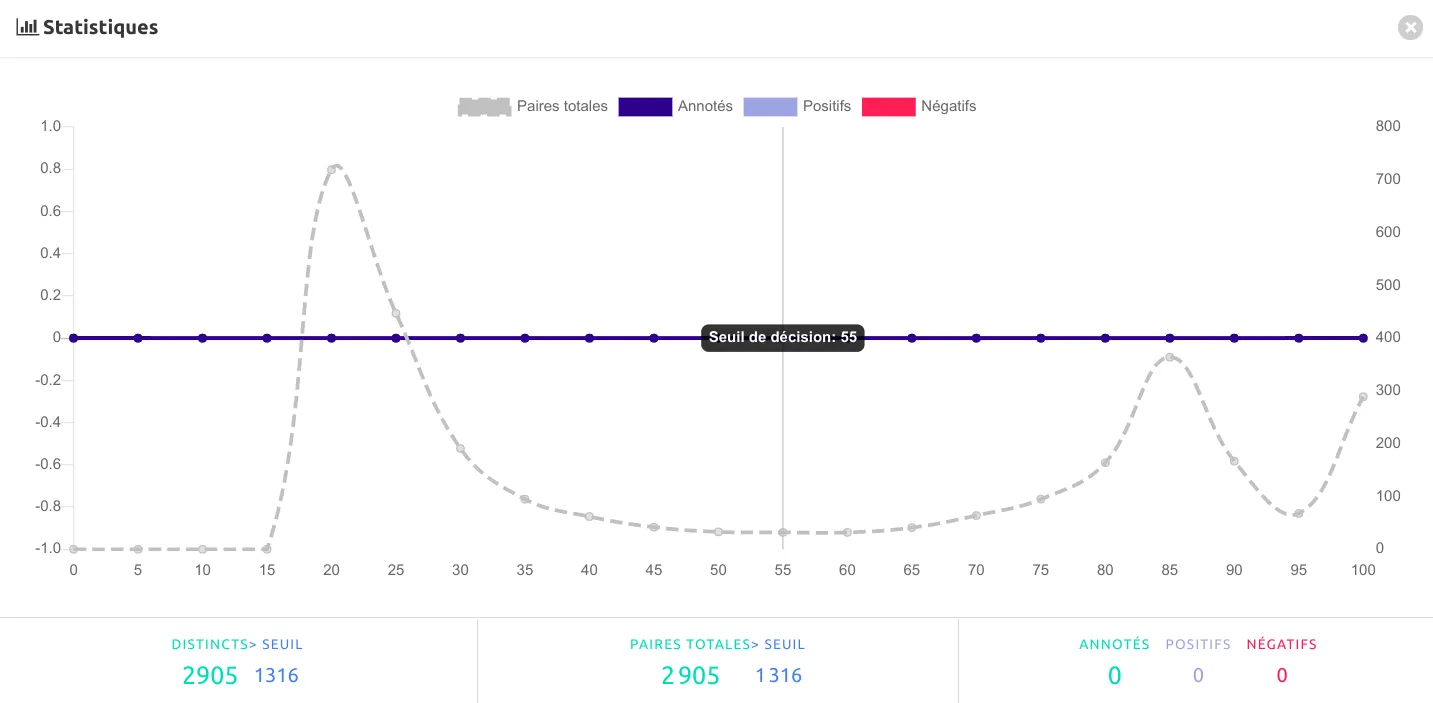
La distribution des scores est accessible via l’onglet statistiques :
 .
.
Filtrer au-dessus de 40 montre déjà de très bons résultats :
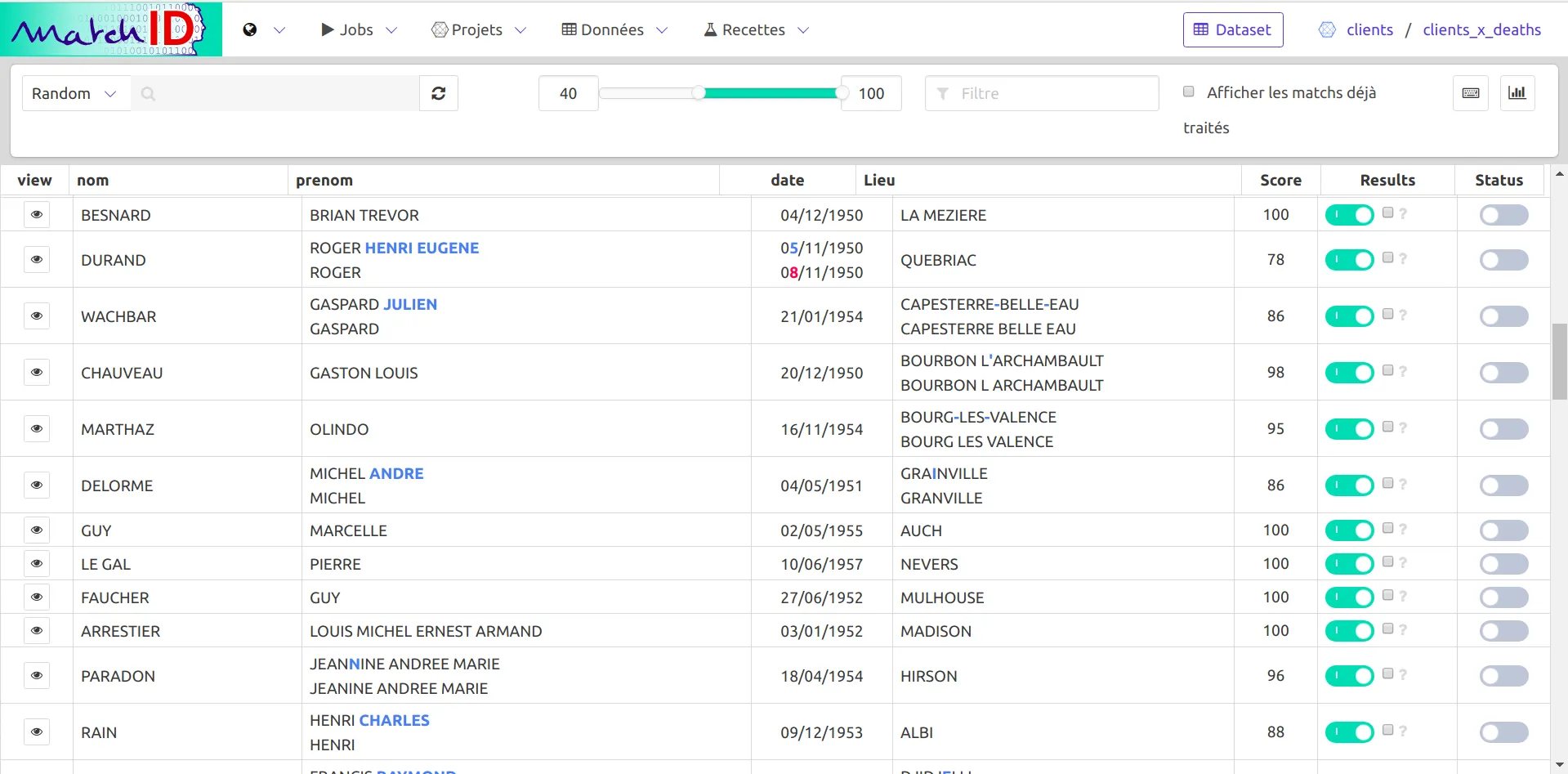
Pour une analyse optimale des résultats, il est recommandé d'annoter un certain nombre de paires pour passer d'une logique de scores de vraisemblance à des scores probabiliste. Néanmoins ce nombre dépendra de la précision souhaitée, ce qui peut être très chronophage. Ainsi, pour garantir que le quantile de scores > 90% est d'au moins 99,9% il faudra annoter au moins 1000 paires.
Pour continuer dans l'apprentissage, vous pouvez passer au tutoriel avancé (avec le machine learning) ou simplement consulter les algorithmes pour comprendre comment adapter au mieux les recettes à vos cas d'usage. La documentation des recettes] vous aidera également à mieux comprendre les possiblités.
Fabien est ingénieur et travaillait au sein de ministères régaliens sur la data et l'IA. Concepteur de matchID et de deces.matchid.io, il développe toujours avec plaisir les algorithmes aussi bien que les UI, sur son temps libre. Depuis 2022, il travaille en IT et IA à Montréal, et reste passionné par les projets d'intérêt général.

Cristian est phD passionné de développement et technologie, expert en deeplearning. Il travaille aujourd'hui au ministère de l'Intérieur, où il a créé IA Flash, et contribue activement à matchID avec la création de l'API décès.

Docteur en droit et diplômé en affaires publiques de l’IEP de Paris, Simon s’est spécialisé dans la transformation des administrations, notamment à travers le numérique. Passionné par ces sujets, il travaille à l’innovation dans les ministères, enseigne à l’université et contribue à MatchID sur les aspects juridiques et financiers.

